Full Digital Marketing and web optimization Guide for Women’s Clothing
#toc background: #f9f9f9;border: 1px solid #aaa;display: table;margin-bottom: 1em;padding: 1em;width: 350px; .toctitle font-weight: 700;text-align: center;
One major setback of Scrapy is that it doesn’t render JavaScript; you need to send Ajax requests to get information hidden behind JavaScript events or use a third-party device such as Selenium. The third option is to use a self-service point-and-click on software, similar to Mozenda. Many corporations keep software program that enables non-technical business customers to scrape web sites by building initiatives using a graphical person interface (GUI). Instead of writing customized code, customers merely load an internet web page right into a browser and click on to determine data that ought to be extracted into a spreadsheet.
This can be a large time saver for researchers that rely on entrance-end interfaces on the web to extract knowledge in chunks. Selenium is a special tool when in comparison with BeautifulSoup and Scrapy.
Finally, the info might be summarized at the next degree of detail, to indicate common costs across a class, for example. To automatically extract data from web sites, a computer program have to be written with the project’s specifications. This computer program can be written from scratch in a programming language or could be a set of instructions input right into a specialised internet scraping software. Web scraping and web crawling discuss with related but distinct actions.
Via Selenium’s API, you’ll be able to truly export the underlying code to a Python script, which may later be used in your Jupyter Notebook or text editor of selection. My little instance makes use of the easy functionality supplied by Selenium for net scraping – rendering HTML that is dynamically generated with Javascript or Ajax.
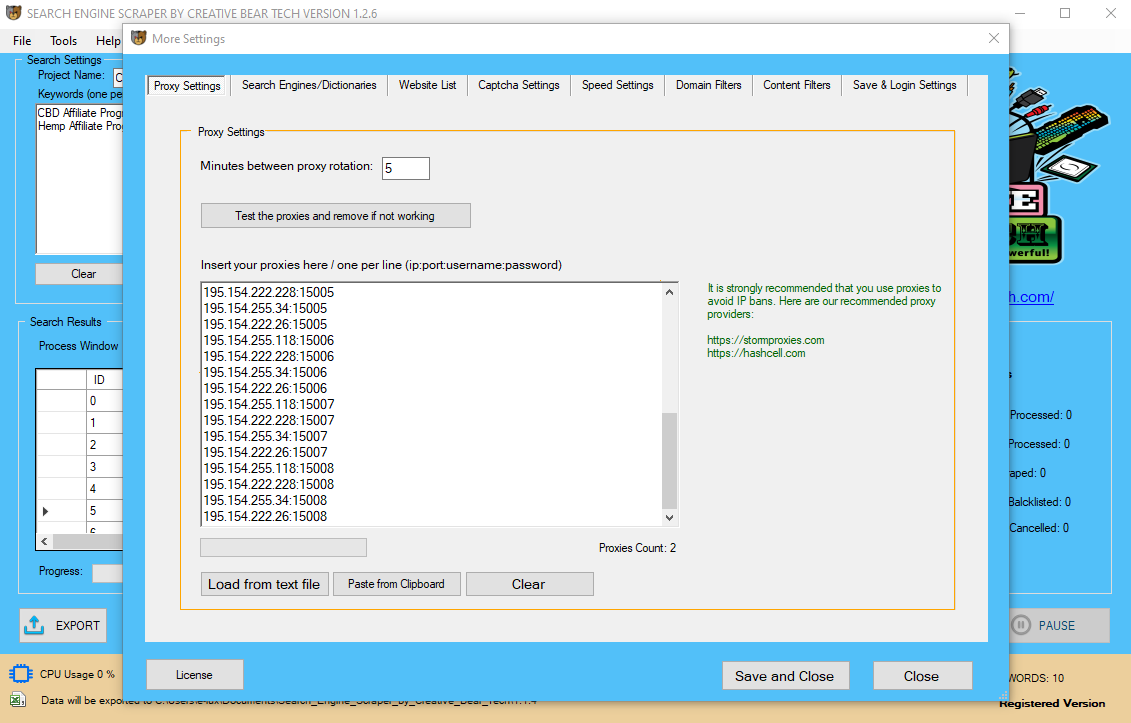
The Selenium-RC (remote-management) device can management browsers through injecting its personal JavaScript code and can be utilized for UI testing. Selenium is an automation testing framework for internet applications/web sites which may also management the browser to navigate the website similar to a human.
However, along with all this selenium is useful after we wish to scrape data from javascript generated content material from a webpage. That is when the information exhibits up after many ajax requests. Nonetheless, each BeautifulSoup and scrapy are perfectly able to extracting data from a webpage. The selection of library boils all the way down to how the data in that specific webpage is rendered.
When you name next_button.click(), the true net browser responds by executing some JavaScript code. I was battling my personal web scraping Python based mostly project due to I-frames and JavaScript stuff whereas utilizing Beautiful Soup. I’ll undoubtedly check out the strategy that you have explained. The first alternative I needed to make was which browser I was going to inform Selenium to make use of. As I typically use Chrome, and it’s built on the open-source Chromium project (also utilized by Edge, Opera, and Amazon Silk browsers), I figured I would strive that first.
Selenium
In beneath loop, driver.get function requires URL however as we’re utilizing hyperlink factor x, it is giving me error and asking for URL. ChromeDriver, which must be installed earlier than we begin scraping. The Selenium net driver speaks directly to the browser utilizing the browser’s own engine to control it. We can easily program a Python script to automate a web browser using Selenium.
How To Catch An Elementnotvisibleexcpetion
Thus, a web scraping project may or may not contain internet crawling and vice versa. Selenium is an open source web testing software that permits users to check internet purposes throughout completely different browsers and platforms. It includes a plethora of software that developers can use to automate web functions including IDE, RC, webdriver and Selenium grid, which all serve completely different purposes. Moreover, it serves the purpose of scraping dynamic net pages, one thing which Beautiful Soup can’t.
Launching The Webdriver
In the early days, scraping was mainly done on static pages – those with known elements, tags, and knowledge. As troublesome initiatives go, though, it’s an easy bundle to deploy in the face of difficult JavaScript and CSS code.
The main problem associated with Scrapy is that it is not a beginner-centric software. However, I had to drop the concept once I discovered it’s not newbie-friendly.
When you open the file you get a totally functioning Python script. Selenium is a framework designed to automate checks on your web utility. Through Selenium Python API, you’ll be able to entry all functionalities of Selenium WebDriver intuitively. It provides a handy method to entry Selenium webdrivers corresponding to ChromeDriver, Firefox geckodriver, and so on. Because of this, many libraries and frameworks exist to help within the development of initiatives, and there’s a massive group of builders who at present build Python bots.

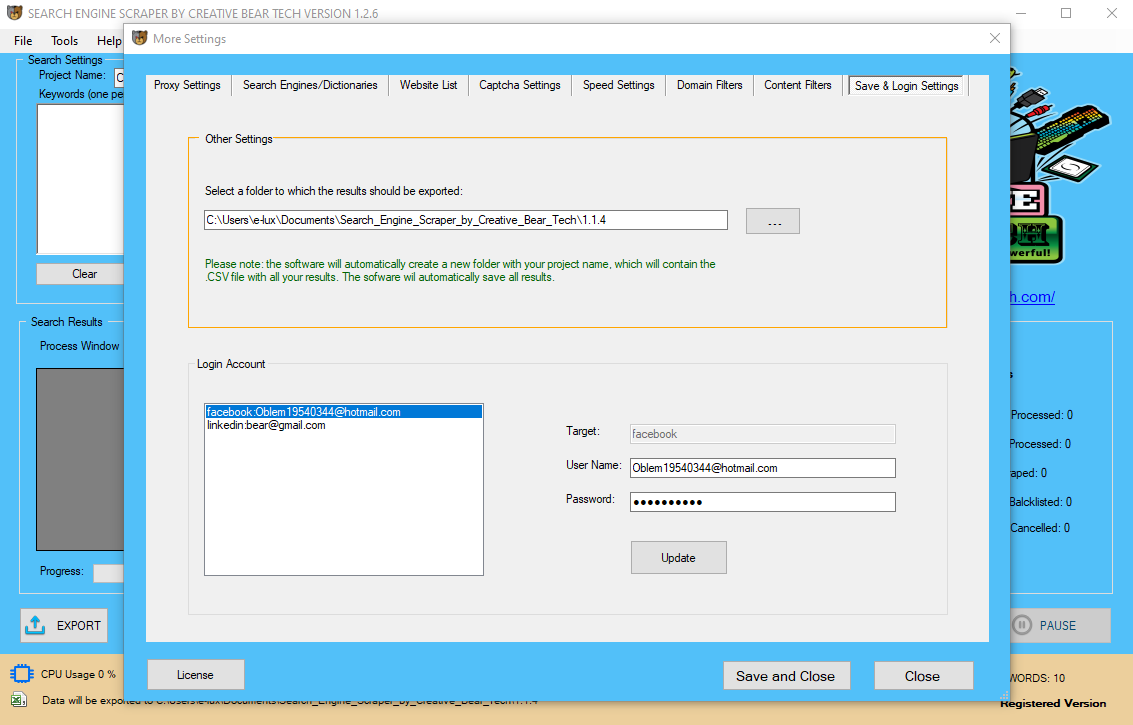
With the Selenium Nodes you have the power of a full-blown browser mixed with KNIME’s processing and knowledge mining capabilities. Your first step, earlier than writing a single line of Python, is to install a Selenium supported WebDriver for your favourite net browser. In what follows, you may be working with Firefox, but Chrome could easily work too. Beautiful Soup is a Python library built particularly to tug data out of HTML or XML files. Selenium, then again, is a framework for testing net functions.
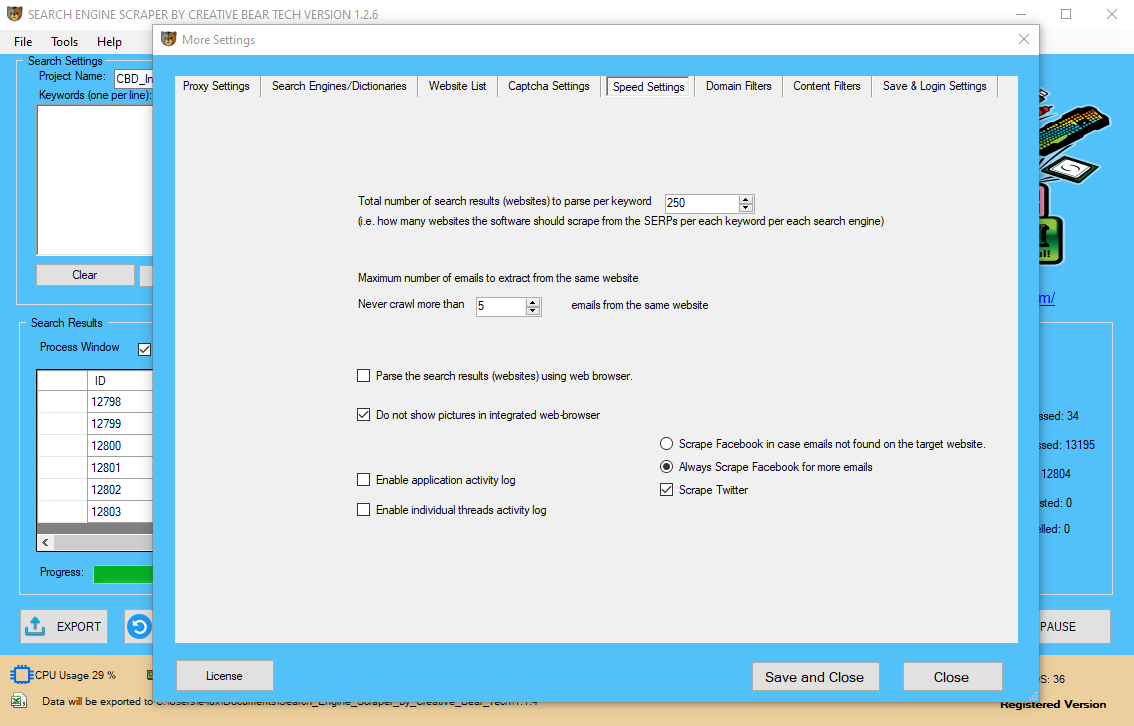
This makes recruitment of developers simpler and also means that assist is less complicated to get when needed from websites similar to Stack Overflow. Besides its popularity, Python has a relatively easy learning curve, flexibility to perform all kinds of duties easily, and a clear coding fashion. Some web scraping tasks are higher suited towards using a full browser to render pages. This might imply launching a full internet browser in the identical way a daily user may launch one; web pages that are loaded on seen on a screen. However, visually displaying web pages is generally unnecessary when internet scraping leads to greater computational overhead.
In recent years, there was an explosion of entrance-end frameworks like Angular, React, and Vue, which are becoming increasingly well-liked. Webpages that are generated dynamically can supply a quicker user expertise; the elements on the webpage itself are created and modified dynamically. These websites are of nice profit, however can be problematic once we wish to scrape data from them.
Selenium is used for net utility automated testing. It automates net browsers, and you can use it to carryout actions in browser environments on your behalf. However, it has since been included into internet scraping.
- Use net scraping when the info you need to work with is available to the general public, however not necessarily conveniently available.
- These web sites are of great benefit, however can be problematic once we wish to scrape data from them.
- Web scraping with Python and Beautiful Soup is an excellent software to have inside your skillset.
- Webpages that are generated dynamically can offer a sooner person experience; the weather on the webpage itself are created and modified dynamically.
- In recent years, there was an explosion of entrance-end frameworks like Angular, React, and Vue, which have gotten increasingly popular.
- The simplest approach to scrape these varieties of internet sites is through the use of an automated internet browser, corresponding to a selenium webdriver, which may be controlled by a number of languages, including Python.
Selenium makes use of a web-driver package deal that may take management of the browser and mimic person-oriented actions to set off desired events. This information will clarify the process of building an internet scraping program that will scrape knowledge and download information from Google Shopping Insights.
To learn more about scraping superior sites, please visit the official docs of Python Selenium. Static scraping was adequate to get the listing of articles, however as we saw earlier, the Disqus comments are embedded as an iframe component by JavaScript.
The Selenium IDE allows you to simply examine parts of an online web page by monitoring your interaction with the browser and offering alternate choices you should use in your scraping. It additionally provides the chance to easily mimic the login experience, which might overcome authentication issues with certain web sites. Finally, the export characteristic offers a fast and simple approach to deploy your code in any script or notebook you select. This information has covered just some aspects of Selenium and internet scraping.
Yet, like many government websites, it buries the information in drill-down links and tables. This often requires “best guess navigation” to search out the particular knowledge you might be looking for. I wished to make use of the general public information offered for the schools inside Kansas in a research project.
I prefer to remove this variable from the equation and use an precise browser internet driver. In this tutorial, you’ll find out how the content material you see within the browser really will get rendered and how to go about scraping it when necessary.
Selenium can send internet requests and likewise comes with a parser. With Selenium, you’ll be able to pull out knowledge from an HTML document as you do with Javascript DOM API.
Scraping the info with Python and saving it as JSON was what I needed to do to get began. In some instances you might choose to make use of a headless browser, which means no UI is displayed. Theoretically, PhantomJS is simply 21 Lead Generation Software For B2B Businesses To Use in 2020 one other internet driver. But, in follow, people reported incompatibility points where Selenium works correctly with Chrome or Firefox and sometimes fails with PhantomJS.
It offers us the freedom we have to efficiently extract the data and retailer it in our most well-liked format for future use. In this text, we’ll learn how to use internet scraping to extract YouTube video information utilizing Selenium and Python.
The Full Python Code
In order to harvest the comments, we will need to automate the browser and work together with the DOM interactively. Web crawling and information extraction is a ache, particularly on JavaScript-based mostly websites.
First, particular person websites may be troublesome to parse for a variety of reasons. Websites may load slowly or intermittently, and their information may be unstructured or discovered inside PDF recordsdata or images. This creates complexity and ambiguity in defining the logic to parse the site. Second, websites can change without discover and in sudden methods.
So, I decided to desert my traditional strategies and take a look at a potential tool for browser-based mostly scraping. A major component right here, something that the majority blogs and tutorials on Selenium will handle, is the WebDriver (pictured here). The WebDriver, should you’re penning this code from scratch, have to be imported and assigned with your browser of selection.
In explicit, you’ll learn how to depend Disqus feedback. Our instruments shall be Python and awesome packages like requests, BeautifulSoup, and Selenium. In order to collect this info, you add a way to the BandLeader class. Checking back in with the browser’s developer instruments, you discover Best Facebook Email extractor 2020 the right HTML elements and attributes to select all the information you want. Also, you only want to get details about the presently taking part in observe if there music is actually enjoying at the time.
There are primary features right here (e.g. rename), however this button is necessary for one cause, to export the code of the take a look at. When this selection is chosen, you can merely select the language (Python in our case) and reserve it to your project folder.
Web scraping tasks have to be set up in a way to detect adjustments after which have to be up to date to precisely gather the same info. Finally, web sites may make use of applied sciences, such as captchas, particularly designed to make scraping difficult. Depending on the insurance policies of the net scraper, technical workarounds may or will not be employed. The precise extraction of information from web sites is normally simply step one in an online scraping project. Further steps often must be taken to wash, remodel, and combination the information before it can be delivered to the top-consumer or application.
Furthermore, initiatives generally are run on servers without displays. Headless browsers are full browsers without a graphical user interface. They require less computing sources and can run on machines without displays. A tradeoff is that they don’t behave exactly like full, graphical browsers. For example, a full, graphical Chrome browser can load extensions while a headless Chrome browser can’t (source).
When JavaScript provides or “hides” content material, browser automation with Selenium will insure your code “sees” what you (as a person) should see. And finally, when you are scraping tables full of information, pandas is the Python data evaluation library that can handle all of it. Gigi Sayfan is a principal software architect at Helix — a bioinformatics and genomics begin-up. His technical expertise consists of databases, low-level networking, distributed techniques, unorthodox consumer interfaces, and general software growth life cycle.
We will then use the NLTK library to wash the information and then construct a model to categorise these videos based mostly on specific categories. The automated net scraping course of described above completes quickly. Selenium opens a browser window you’ll be able to see working. This allows me to indicate you a display screen capture video of how briskly the method is. You see how briskly the script follows a link, grabs the info, goes again, and clicks the subsequent link.
The easiest way to scrape these varieties of internet sites is through the use of an automatic internet browser, similar to a selenium webdriver, which can be managed by several languages, together with Python. Web scraping with Python and Beautiful Soup is an excellent tool to have within your skillset. Use internet scraping when the information you have to work with is on the market to the general public, however not necessarily conveniently obtainable.
Luckily, the web page player adds a “enjoying” class to the play button every time music is enjoying and removes it when the music stops. First, bandcamp designed their web site for humans to get pleasure from using, not for Python scripts to entry programmatically.
Browser Profile Firefox_path
My go-to language for internet scraping is Python, because it has nicely-built-in libraries that can typically handle the entire performance required. And certain sufficient, a Selenium library exists for Python. This would enable me to instantiate a “browser” – Chrome, Firefox, IE, and so forth. – then pretend I was using the browser myself to realize entry to the information I was on the lookout for. And if I didn’t want the browser to truly seem, I may create the browser in “headless” mode, making it invisible to any consumer.
It allows for instantiating a browser occasion utilizing a driver, then uses instructions to navigate the browser as one would manually. Web scraping has been used to extract knowledge from websites nearly from the time the World Wide Web was born.
Scraping Data From Multiple Sites In Webdriver Selenium
Most generally, programmers write customized software program programs to crawl particular websites in a pre-decided trend and extract information for several specified fields. Selenium is a framework which is designed to automate check for internet applications. You can then write a python script to regulate the browser interactions automatically such as link clicks and form submissions.
